

Imagine que você tem um robô que quer aprender a se movimentar melhor, como um ser humano de verdade. Provavelmente ele faria isso do mesmo jeito que os novos humanos (os bebês e crianças) fazem: imitando humanos adultos.
No mundo da robótica, essa “imitação” é facilitada através de uma ajuda virtual, que são basicamente video games que servem como simuladores. Mas aí vem um novo obstáculo, porque botar a teoria na prática ainda é o maior desafio. É o descompasso entre as simulações e a realidade.

É como se você aprendesse a andar de bicicleta em um video-game e depois fosse tentar na vida real.
Enfim, os robôs humanóides (aqueles que tem a forma humana, com cabeça tronco e membros, etc) são mais ou menos a interseção entre um chatGPT e um humano.
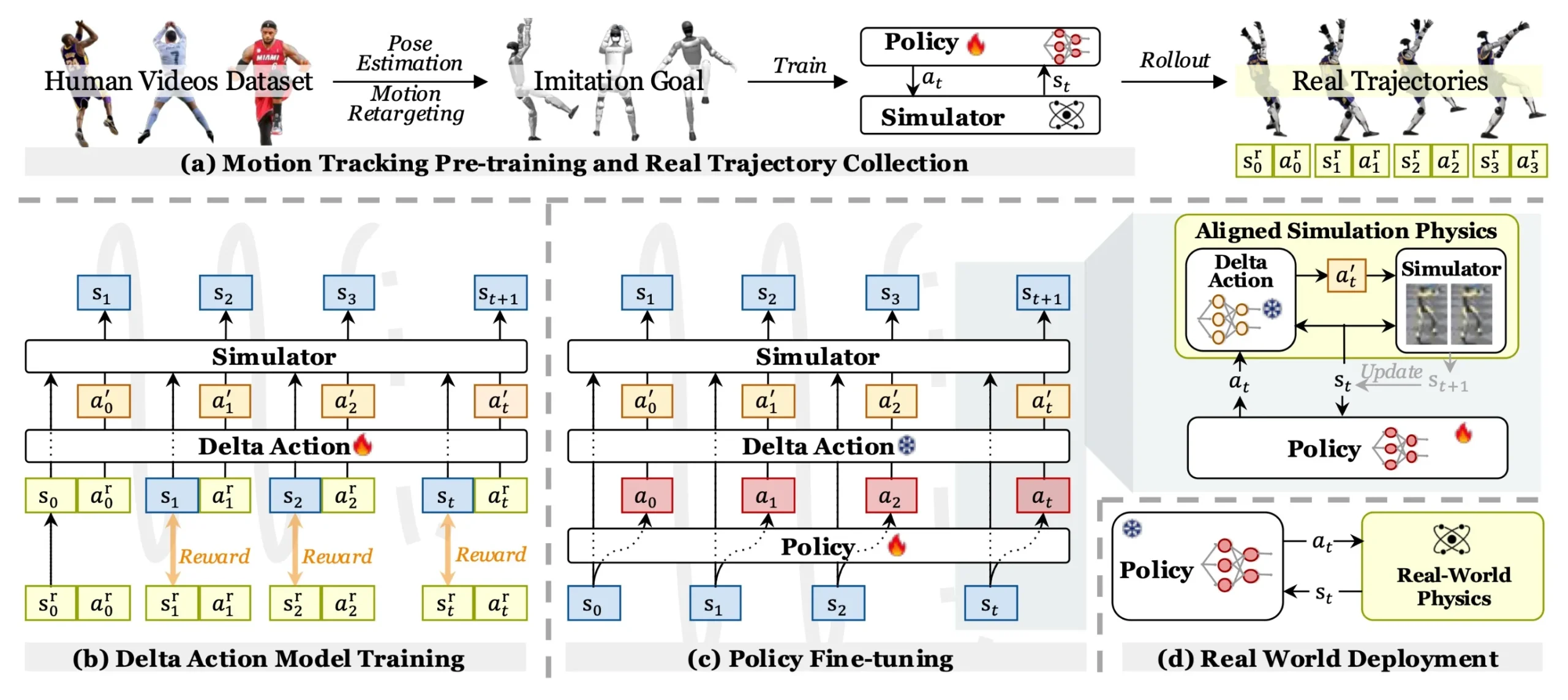
Pensando nisso alguns pesquisadores das universidades Carnegie Mellon e Stanford desenvolveram o ASAP, uma estrutura inovadora que está redefinindo como robôs humanóides aprendem habilidades ágeis ao alinhar simulações com a física do mundo real.
Funcionamento e Impacto
A estrutura do ASAP funciona em duas etapas. Primeiramente, movimentos são pré-treinados em simulação usando dados de movimentos humanos.
E que humanos! Cristiano Ronaldo, Kobe Bryant, LeBron James, entre outros. Afinal, se é para imitar, que imitem os melhores. Imagine isso daqui poucas décadas, a velocidade com que vão aprender com nossos melhores humanos.
Em seguida, um modelo de ação delta é treinado para ajustar as discrepâncias quando esses movimentos são aplicados no mundo real. Isso permite que robôs, como o Unitree G1, realizem movimentos anteriormente inexequíveis, melhorando a agilidade e a coordenação geral.
Método
- Pré-treinamento de rastreamento de movimento e coleta de trajetória real:
com os movimentos humanoides redirecionados de vídeos humanos, pré-treinamos várias políticas de rastreamento de movimento para implementar trajetórias do mundo real; - Treinamento
do modelo de ação delta Com base nos dados de implementação do mundo real, treinamos o modelo de ação delta minimizando a discrepância entre o estado de simulação e o estado do mundo reals_ts^r_t; - Política Ajuste
fino Congelamos o modelo de ação delta, incorporamo-lo ao simulador para alinhar a física do mundo real e, em seguida, ajustamos a política de rastreamento de movimento pré-treinada; - Implantação
no mundo real Por fim, implantamos a política ajustada diretamente no mundo real sem o modelo de ação delta.
clique na imagem para ampliar
Um Salto para o Futuro
Os testes realizados demonstraram que o ASAP não só reduz o erro de rastreamento, mas também aumenta significativamente a agilidade dos robôs. Isso sugere um futuro brilhante para aplicações diversas, desde a automação industrial até auxílio em fisioterapia.
Promessa de Avanços Futurísticos
Com a capacidade de alinhar simulação e realidade, o ASAP pode abrir portas para robôs que rivalizam com habilidades humanas em ambientes controlados e imprevisíveis. A inovação não só promete transformar a indústria de robótica, mas também potencializar a aplicação de robôs em várias indústrias e serviços pessoais.







