
Peguei emprestado o título de um verso de uma canção do Bob Dylan que adoro, Ballad of a Thin Man, mas bem que poderia ser “a sinuca-de-bico dos LLMs”. Ou ainda, a pergunta “de onde vem o conteúdo das IAs generativas?”.
A verdade é que não é surpresa alguma para quem é do meio que estamos ficando sem dados para treinar as novas versões de LLM – Large Language Models (quem tiver interesse, gravei dois vídeos de introdução sobre os Grandes Modelos de Linguagem, com uma pegada técnica mais acessível aos leigos – parte 1 e parte 2). A questão é saber o quanto estamos próximos do limite. Essa semana, conversei com alguns colegas sobre o assunto. Em especial, Mark Cummins, compartilhou algumas estimativas da quantidade total de texto de Internet disponível no mundo. A estimativa do Mark está baseada nas principais fontes públicas e privadas existentes hoje.
Vamos pegar como base o Llama 3 (quem assistir aos vídeos, saberá o motivo pelo qual o Llama é usado como benchmarking). O Llama 3 foi treinado com base em 15 trilhões de tokens (mais ou menos 11 trilhões de palavras), como pode ser observado na Tabela 1. Só para efeito de comparação, segundo o Mark, a quantidade representa aproximadamente 100.000 vezes o que um ser humano necessita para aprender um idioma.
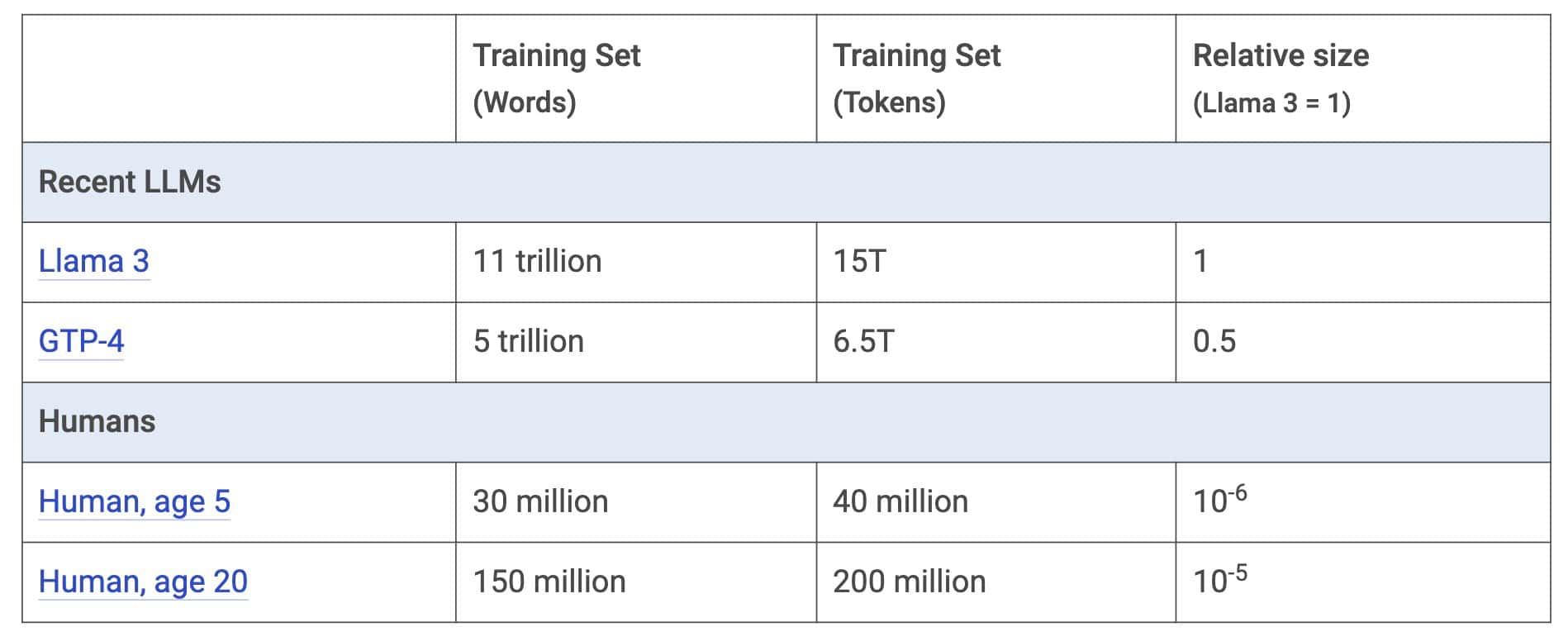
Tabela 1: Escala dos LLMs mais recentes. Fonte: Mark Cummins.
A principal fonte de dados para treinar uma LLM é retirada da Web por meio de web scraping. O web scraping é uma técnica de mineração de textos, feita por meio de um web crawler , que navega pela rede mundial baixando páginas de internet (websites, documentos, vídeos, imagens e o que mais se quiser). Existem alguns repositórios, como o Common Crawl, em que é possível conseguir facilmente bilhões de páginas que foram sendo “capturadas” ao longo dos anos. É possível retirar do Common Crawl, por exemplo, mais de 100 trilhões de tokens – embora boa parte desse material seja composto por lixo ou páginas duplicadas.
Há alguns datasets filtrados disponíveis, com tokens mais qualificados, como o Fineweb, que traz cerca de 15 trilhões de tokens (Tabela 2).
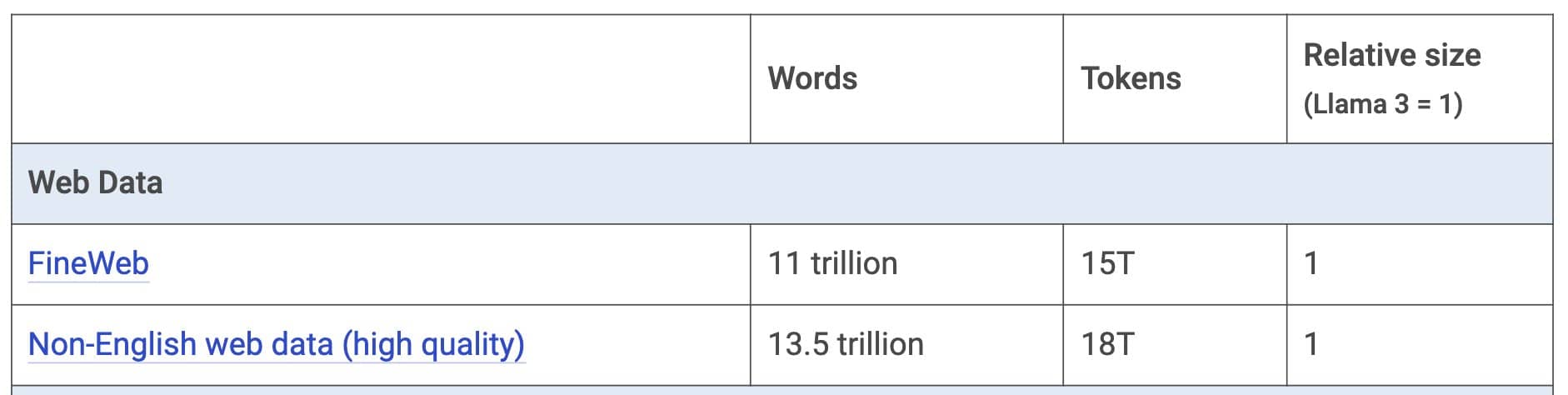
Tabela 2: Dados da Web qualificados. Fonte: Mark Cummins.
Se a leitora ou o leitor mais atento comparar as duas tabelas, perceberá que o Llama 3 foi treinado com basicamente todo o texto em inglês de qualidade disponível na Internet.
O inglês corresponde a, aproximadamente, 45% da Web. A princípio, seria possível aumentar os dados disponíveis para treinamento usando texto multilíngue, mas empiricamente isso não ajuda os modelos atuais, que aprendem em inglês. Apesar de podermos nos comunicar com modelos, como o ChatGPT, em outras línguas, a IA em si “entende” e “fala” apenas inglês (o que existe é uma etapa de tradução que permite a comunicação multilíngue). É preciso então desenvolver um novo modo de treinamento que possa fazer uso eficaz dos dados multilíngues.
Datasets como o disponibilizado pela Common Crawl e FineWeb são montados basicamente com htmls. Qualquer conteúdo disponibilizado em PDF ou renderizado dinamicamente, é ignorado. O que existe por trás de um login (materiais proprietários), dificilmente é capturado. Portanto, há mais dados disponíveis em diferentes formatos para serem usados. Vamos ver alguns exemplos:
Artigos acadêmicos e patentes (Tabela 3) poderiam adicionar cerca de 1,2 trilhões de tokens. É mais trabalhoso extrair conteúdo de PDFs, mas o fato de serem textos de alta qualidade os tornam muito valiosos. A questão é entrar em acordo financeiro com os donos do conteúdo (se não estiverem publicados como dados abertos).
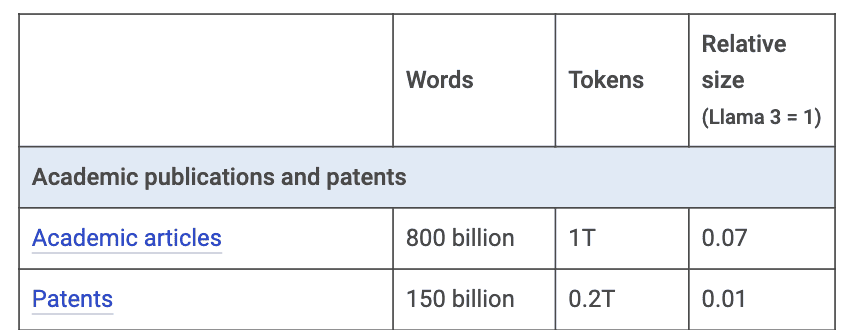
Tabela 3: Estimativa de tokens vindos de artigos acadêmicos e patentes. Fonte: Mark Cummins.
Livros são outra grande fonte de conteúdo, mas menos acessíveis. O Google Books, por exemplo, pode gerar quase 5 trilhões de tokens (Tabela 4), mas está disponível apenas para o Google. Esta inclusive, pode ser a maior fonte proprietária de tokens de alta qualidade que existe.
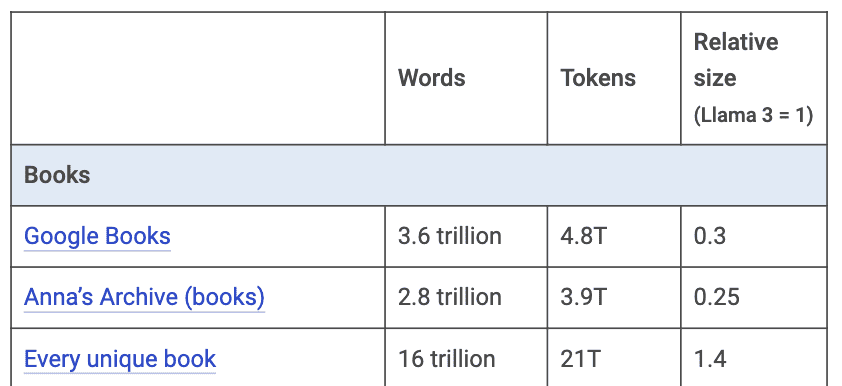
Tabela 4: Estimativa de tokens vindo de livros. Fonte: Mark Cummins.
Anna’s Archive, é uma biblioteca sombra (antigamente conhecida como “pirata”) com quase 4 trilhões de tokens de e-books. Aqui, há inúmeros problemas legais para se conseguir o conteúdo, mas reconheço que não seria um grande desafio técnico se alguém decidir que vale a pena “capturar” esse material (afinal, “ladrão que rouba ladrão…”). De qualquer forma, os e-books, de uma maneira geral, poderiam gerar outros 21 trilhões de tokens.
Vamos falar das mídias sociais agora (Tabela 5). O X (antigo Twitter) poderia gerar cerca de 11 trilhões de tokens e o Weibo (o Twitter chinês) outros 38 trilhões. Confesso que o número me surpreendeu, mas creio que se fizermos uma filtragem de qualidade neles, os números devem cair bastante. O Facebook é ainda maior, o Mark estimou em 140 trilhões de tokens, embora exista a possibilidade que seja ainda maior (Zuckerberg e cia estão sentados em uma verdadeira mina de ouro). No entanto, legislações a respeito de privacidade de dados indicam que, provavelmente, esse material não será utilizado.
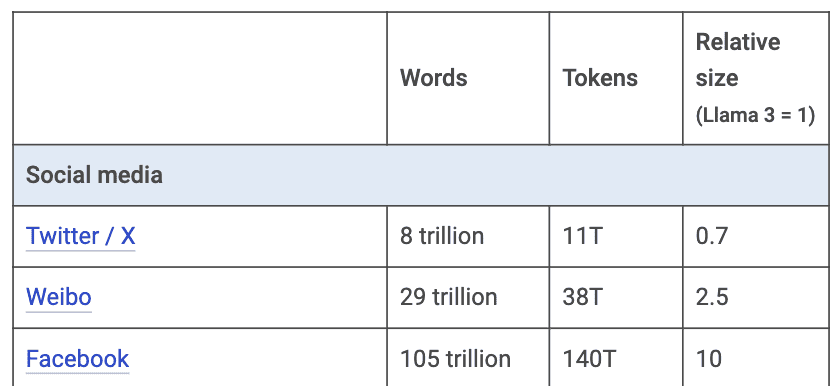
Tabela 5: Estimativa de tokens vindo das mídias sociais. Fonte: Mark Cummins.
No lançamento do Llama 3, foi relatado que “nenhum dado de usuário da Meta foi usado”, apesar do próprio Zuckerberg se gabar de que possui um corpus maior do que todo o Common Crawl. Creio que, pelo menos no curto prazo, é possível considerarmos esse conteúdo off-limits.
Áudio transcrito (Tabela 6) é outra fonte considerável de tokens disponíveis publicamente. É amplamente aceito que a OpenAI desenvolveu o Whisper (rede neural para reconhecimento de fala) com essa finalidade. YouTube e TikTok possuem 7 trilhões e 5 trilhões, respectivamente. Podcasts têm um décimo desse tamanho, mas com uma qualidade muito superior, o que também os tornam muito valiosos.
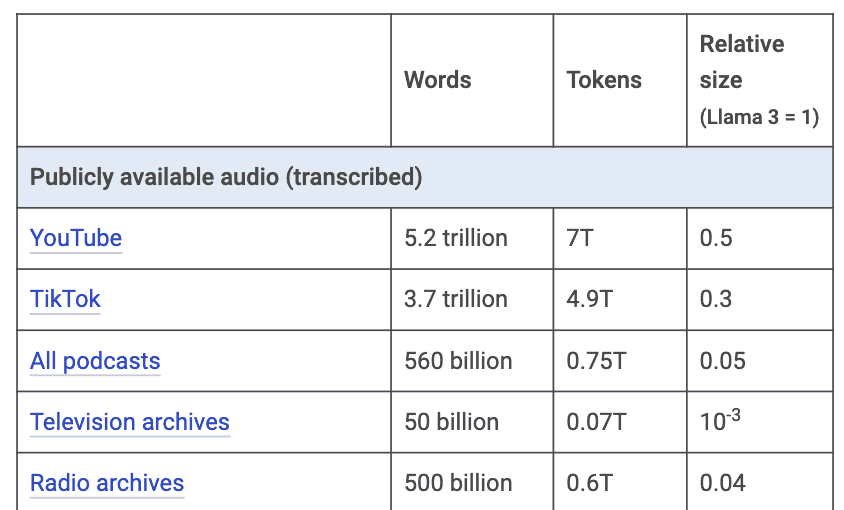
Tabela 6: Estimativa de tokens vindo de áudio transcrito. Fonte: Mark Cummins.
O conteúdo de arquivos digitalizados de TV é bem pequeno, possivelmente não valeria o esforço. O rádio representa potencialmente alguns trilhões de tokens (se estivessem digitalizados em bons arquivos), mas infelizmente o que sabemos desse conteúdo é que são pequenos e fragmentados. Na prática, não seria possível obter mais do que algumas centenas de bilhões de tokens, menos do que os podcasts.
A seguir vêm os códigos de programação (Tabela 7). Código é um tipo de texto muito importante para a IA (não se esqueçam, é a “língua” dos computadores). Existem 0,75 trilhões de tokens de código público, em repositórios como GitHub ou em comunidades Q&A de desenvolvedores (como o StackOverflow). A quantidade total de código já escrito até hoje pode chegar a 20 trilhões, embora grande parte dele seja privado ou esteja perdido.
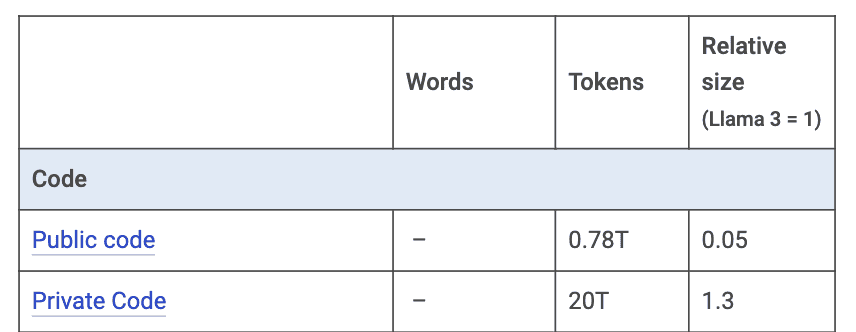
Tabela 7: Estimativa de tokens vindo de códigos de programação. Fonte: Mark Cummins.
Chegamos aos dados privados (Tabela 8). Existem muito mais dados privados do que públicos. Registros de mensagens instantâneas, por exemplo, podem chegar a 650 trilhões de tokens. E-mails armazenados, talvez cheguem a 1.200 trilhões. É estimado que somente o Gmail possua 300 trilhões – assim como Zuckerberg, Larry Page e Sergey Brin também estão sentados em uma mina de ouro, embora submetidos às mesmas restrições de privacidade da Meta.
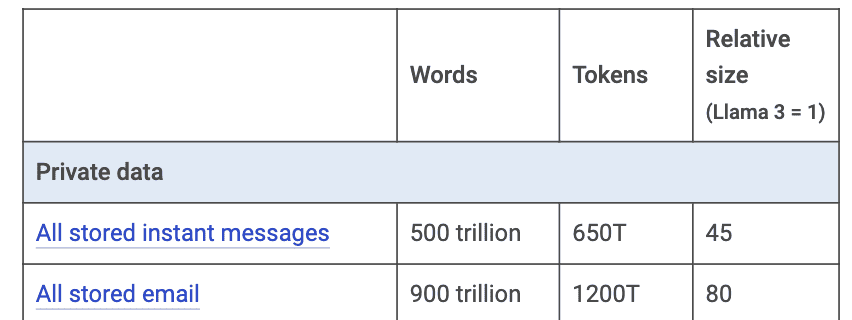
Tabela 8: Estimativa de tokens vindo de dados privados. Fonte: Mark Cummins.
Mark me disse que não consegue imaginar nenhum LLM comercial fazendo uso amplo desses dados, devido às óbvias questões de privacidade. No entanto, uma agência de inteligência (com a NSA ou CIA) poderia fazê-lo. De qualquer forma, a estimativa dele para o conteúdo total gerado pelos seres-humanos é gigantesca (Tabela 9).
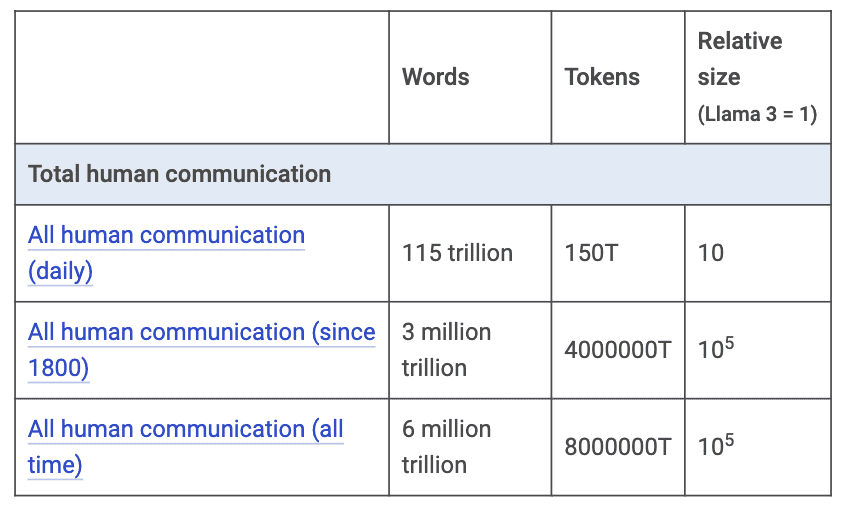
Tabela 9: Estimativa de tokens gerados pelos seres-humanos. Fonte: Mark Cummins.
Se esses dados fossem digitalizados ou canalizados para o treinamento de IA, não haveria limite de conteúdo disponível. No entanto, essa não é a realidade. Os LLMs atuais são treinados com um conteúdo disponível de 15 trilhões de tokens públicos. Possivelmente, com muito esforço, poderíamos expandir para 25 ou 30 trilhões, mas não muito mais. Adicionando dados que não estejam em inglês, poderíamos chegar a 60 trilhões. Esse me parece ser o limite máximo de conteúdo disponível.
Dados privados são muito maiores do que os públicos usados atualmente. As postagens do Facebook ultrapassam 140 trilhões, o Google tem cerca de 300 trilhões de tokens no Gmail e todos os dados privados, em todos os lugares, podem gerar 2.000 trilhões de tokens. É possível desenvolver técnicas de preservação da privacidade que permita treinar modelos públicos em dados privados, mas as consequências que um erro pode gerar me parecem tão grandes (na realidade, enormes) que não consigo imaginar isso acontecendo (pelo menos no curto prazo).
Para concluir, temos disponíveis 15 trilhões de tokens neste momento. Mesmo com um esforço gigantesco, há no máximo de 2x a 4x mais conteúdo disponível em dados públicos. Historicamente, o salto entre cada geração de modelo exigiu 10x mais dados de treinamento. Portanto, novas ideias para “alimentar” o aprendizado das IAs serão necessárias em breve. É ou não uma sinuca-de-bico?





